Type: Software
Status: POC
Tech Stack: Python, FastAPI, SQLAlchemy (async), Celery 5, Redis 7, PostgreSQL 16, faster-whisper/WhisperX/OpenAI Whisper, PyTorch (CUDA 12.6), React 18, Vite, TypeScript, Docker
Problem Statement
Transcription of meetings, interviews, and conferences requires not only speech-to-text but also speaker recognition (who said what?). Cloud-based services are expensive and problematic from a data privacy perspective (GDPR). Local alternatives rarely offer comparable quality, no provider comparison, and no admin dashboard for monitoring quality and performance of different Whisper variants.
Description
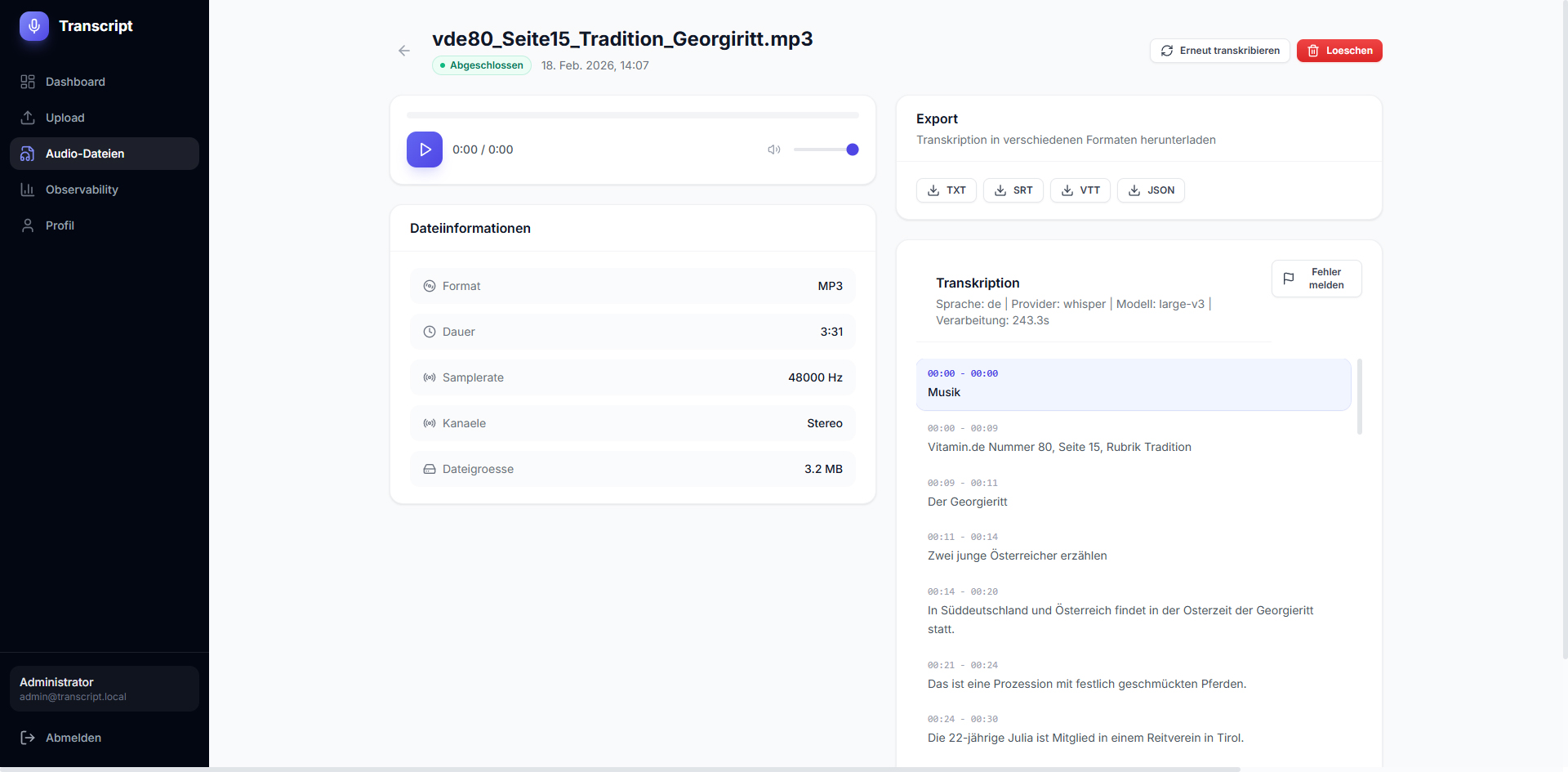
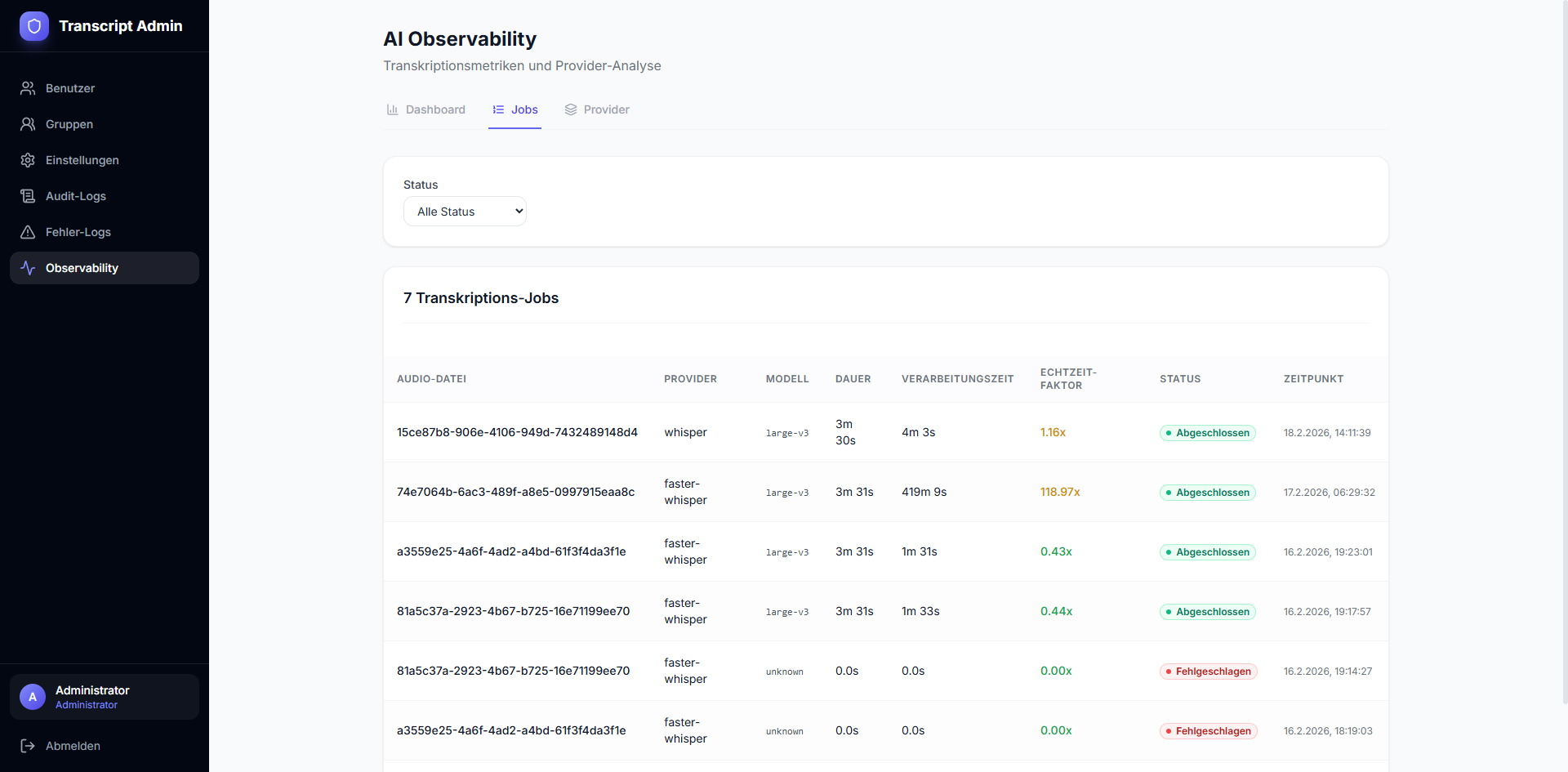
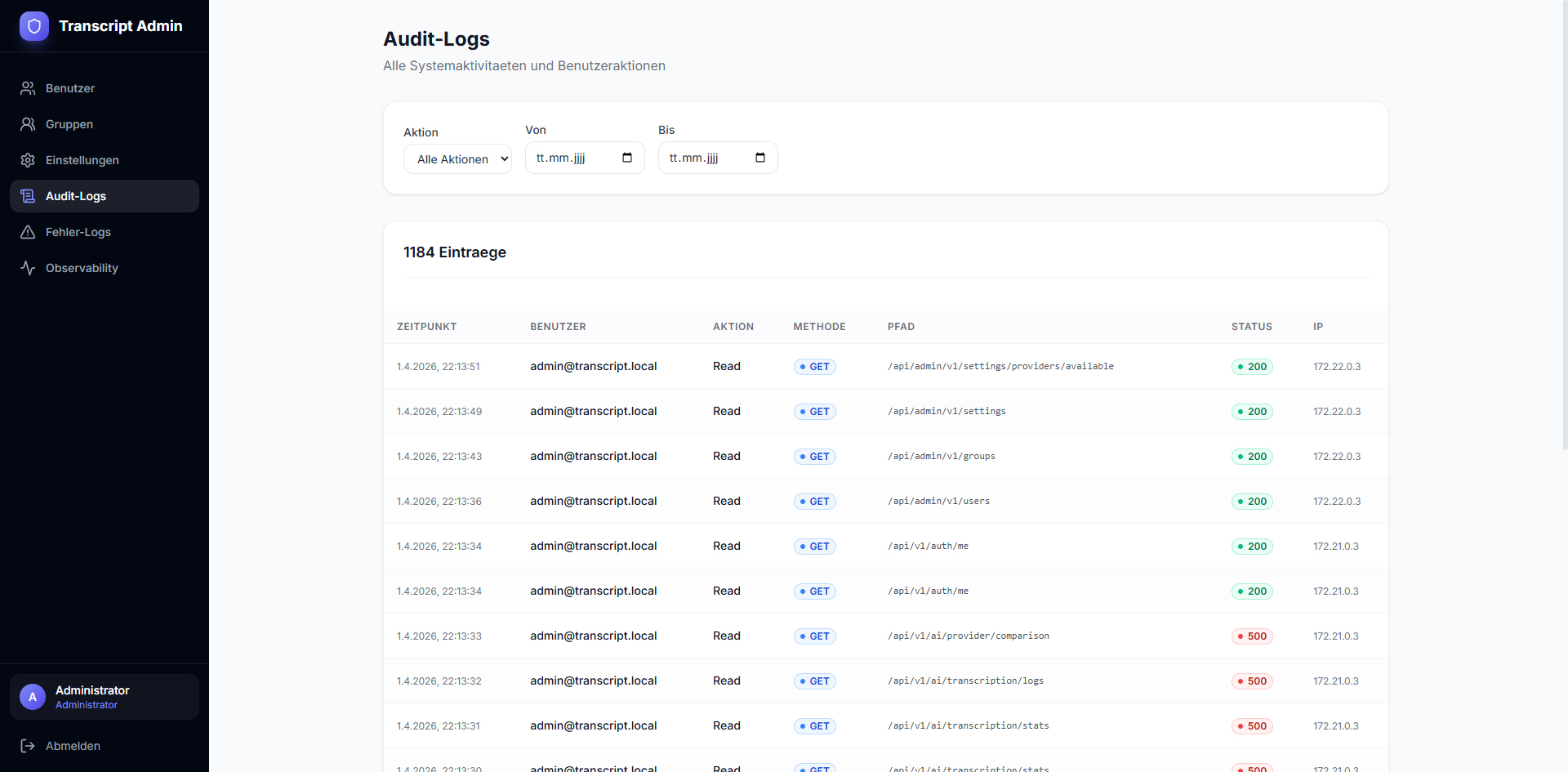
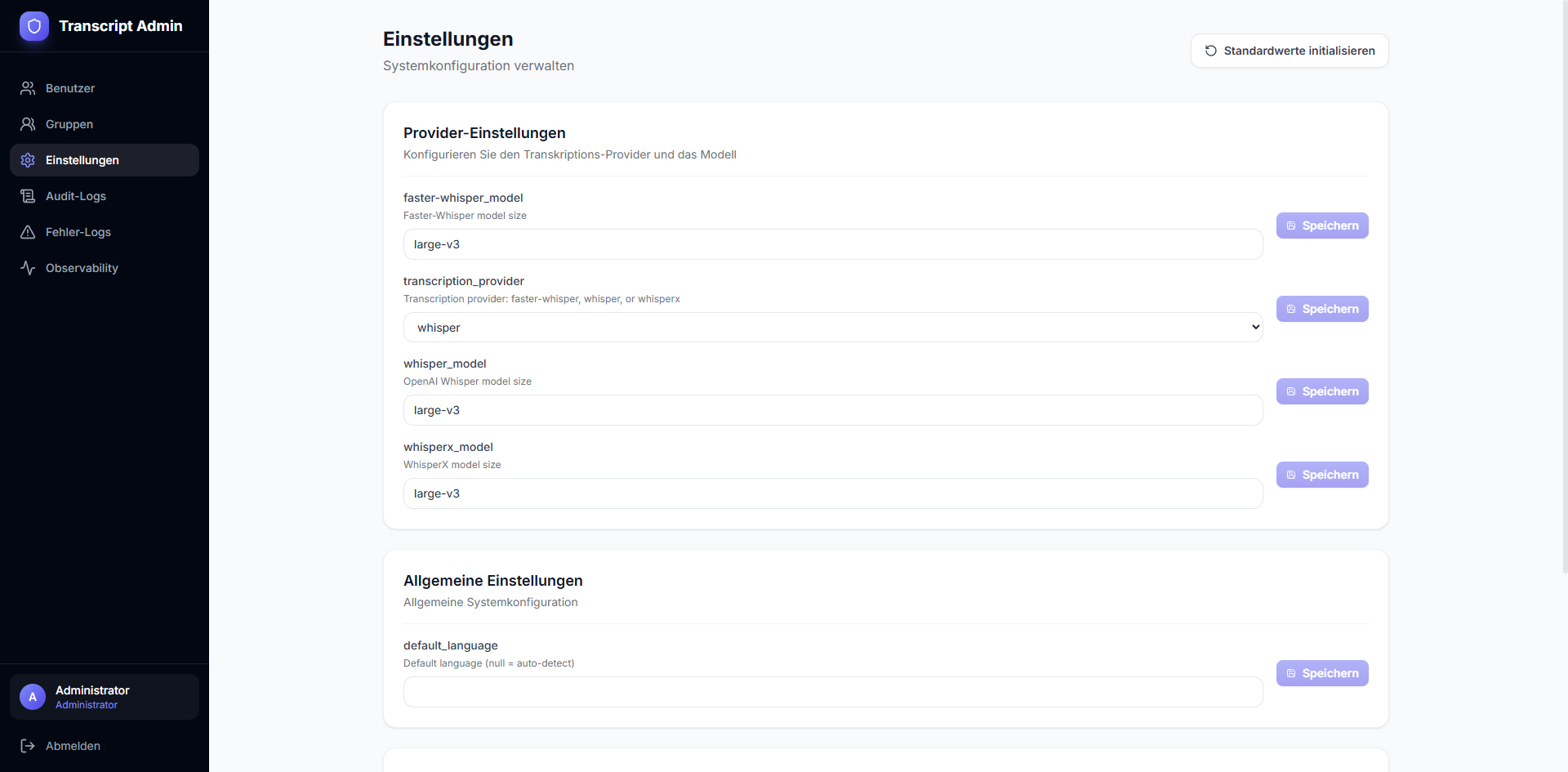
A complete transcription platform with three Whisper variants (faster-whisper, OpenAI-Whisper, WhisperX), automatic GPU acceleration (CUDA), optional speaker diarization, and provider selection per upload. Offers a user frontend and admin dashboard with observability (provider comparison, job logs, error rates, charts), user/group management, audit logs, and export functions.
Use Case
Upload audio files and automatically convert them to text — with recognition of who is speaking.
Link: https://github.com/rawk7000/transcript (private repo)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}